滚动/时间序列预测
使用 tsfresh 提取的特征可用于许多不同的任务,例如时间序列分类、压缩或预测。本节解释了我们如何将这些特征用于时间序列预测。
假设您有某只股票(例如 Apple)在 100 个时间步的收盘价。现在,您想构建一个基于特征的模型来预测 Apple 股票未来的价格。您可以移除最后一个价格值(今天的),然后从直到今天的时间序列中提取特征来预测今天的价格。但这只会给您一个训练示例。相反,您可以重复此过程:在您的股票价格时间序列中的每一天,移除当前值,提取直到该值的时间特征,然后训练以预测当天(您移除的值)的值。您可以将其视为在您已排序的时间序列数据上滑动一个截取窗口:在每个滑动步骤中,您提取通过截取窗口看到的数据来构建一个新的、更小的时间序列,并仅在此时间序列上提取特征。然后继续滑动。在 tsfresh 中,在您的数据上滑动截取窗口以创建更小的时间序列截取片段的过程称为 rolling。
Rolling 是一种将单个时间序列转换为多个时间序列的方法,每个时间序列都比前一个晚一个(或 n 个)时间步结束。tsfresh 中实现的滚动工具可帮助您将数据重塑(并滚动)为一种格式,您可以在此格式上应用通常的 tsfresh.extract_features() 方法。这意味着提取时间序列窗口的步骤和特征提取步骤是分开的。
请注意,“时间”在此处不一定指时钟时间。支持的 数据格式 中 DataFrame 的“sort”列为每个测量值提供了一个顺序状态。在时间序列的情况下,这可以是 时间 维度,而在其他情况下,这可以是位置、频率等。
下图说明了该过程
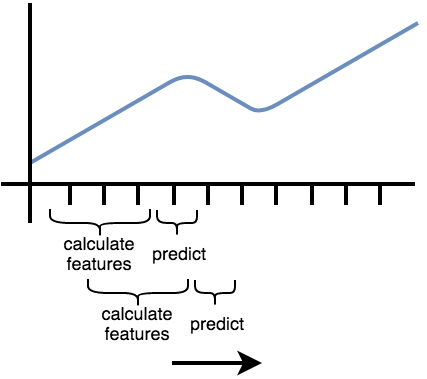
另一个示例可以在流数据中找到,例如在工业4.0应用中。在这种情况下,您通常一次获取一行新数据,并用它来预测机器故障等。要训练您的模型,您可以假装正在流式传输数据,通过在经过一个时间步后将数据馈送给分类器,再在经过前两个时间步后馈送数据,以此类推。
在 tsfresh 中,滚动是通过辅助函数 tsfresh.utilities.dataframe_functions.roll_time_series() 实现的。此外,我们提供 tsfresh.utilities.dataframe_functions.make_forecasting_frame() 方法作为一个方便的包装器,用于快速为给定序列构建容器和目标向量。
让我们来看一个例子,了解它是如何工作的
滚动机制
我们来看下面的扁平化 DataFrame 示例,这是 tsfresh 适合的格式(参见 数据格式)。请注意,滚动也适用于所有其他时间序列格式。
id |
time |
x |
y |
|---|---|---|---|
1 |
1 |
1 |
5 |
1 |
2 |
2 |
6 |
1 |
3 |
3 |
7 |
1 |
4 |
4 |
8 |
2 |
8 |
10 |
12 |
2 |
9 |
11 |
13 |
在上面的扁平化 DataFrame 中,我们在 4 个或 2 个时间步长(1、2、3、4、8、9)测量了两个不同实体(id 1 和 2)的两个传感器 x 和 y 的值。
如果您想跟着做,这里是生成此数据的 Python 代码
import pandas as pd
df = pd.DataFrame({
"id": [1, 1, 1, 1, 2, 2],
"time": [1, 2, 3, 4, 8, 9],
"x": [1, 2, 3, 4, 10, 11],
"y": [5, 6, 7, 8, 12, 13],
})
现在,我们可以使用 tsfresh.utilities.dataframe_functions.roll_time_series() 来获取连续的子时间序列。您可以想象一个窗口在您的时间序列数据上滑动,并提取出通过该窗口看到的所有数据。有三个参数可以调整窗口:
max_timeshift 定义了窗口的最大大小。提取的时间序列的最大长度将是 max_timeshift + 1。(它们也可以更小,因为开头的时间戳具有较少的过去值)。
min_timeshift 定义了每个窗口的最小大小。较短的时间序列(通常在开头)将被省略。
高级设置:rolling_direction:如果您想沿正向(递增排序)或负向(递减排序)滑动。您很少需要负向,因此您可能不想更改默认设置。此参数的绝对值决定了您希望每次截取步骤移动多少。
列参数与通常的 数据格式 中的相同。
让我们看看我们的数据样本会发生什么
from tsfresh.utilities.dataframe_functions import roll_time_series
df_rolled = roll_time_series(df, column_id="id", column_sort="time")
新数据集仅包含旧数据集中的值,但具有新的 id。排序列的值(在本例中是 time)也被复制。如果您按 id 分组,您将得到以下部分(或“窗口”)
id |
time |
x |
y |
|---|---|---|---|
(1,1) |
1 |
1 |
5 |
id |
time |
x |
y |
|---|---|---|---|
(1,2) |
1 |
1 |
5 |
(1,2) |
2 |
2 |
6 |
id |
time |
x |
y |
|---|---|---|---|
(1,3) |
1 |
1 |
5 |
(1,3) |
2 |
2 |
6 |
(1,3) |
3 |
3 |
7 |
id |
time |
x |
y |
|---|---|---|---|
(1,4) |
1 |
1 |
5 |
(1,4) |
2 |
2 |
6 |
(1,4) |
3 |
3 |
7 |
(1,4) |
4 |
4 |
8 |
id |
time |
x |
y |
|---|---|---|---|
(2,8) |
8 |
10 |
12 |
id |
time |
x |
y |
|---|---|---|---|
(2,9) |
8 |
10 |
12 |
(2,9) |
9 |
11 |
13 |
现在,您可以在滚动后的数据上运行通常的特征提取过程
from tsfresh import extract_features
df_features = extract_features(df_rolled, column_id="id", column_sort="time")
您将得到为上述每个部分生成的特征,然后您可以使用这些特征来训练您的预测模型。
变量 |
x__abs_energy |
x__absolute_sum_of_changes |
… |
|---|---|---|---|
id |
… |
||
(1,1) |
1.0 |
0.0 |
… |
(1,2) |
5.0 |
1.0 |
… |
(1,3) |
14.0 |
2.0 |
… |
(1,4) |
30.0 |
3.0 |
… |
(2,8) |
100.0 |
0.0 |
… |
(2,9) |
221.0 |
1.0 |
… |
例如,id 为 (1,3) 的特征是使用 id=1 的数据提取的,直到并包括 t=3(即 t=1、t=2 和 t=3)。
如果您想训练一个用于预测的模型,tsfresh 还提供了函数 tsfresh.utilities.dataframe_functions.make_forecasting_frame(),它将帮助您正确匹配目标向量。此过程在下图中可视化。它显示了紫色的、滚动的子时间序列如何用作构建特征矩阵 X 的基础(如果 f 是 extract_features 函数)。绿色数据点需要由模型预测,并用作目标向量 y 中的行。请注意,这仅适用于单个 id 和 kind 的一维时间序列。

参数和实现说明
上面的示例演示了创建新时间序列的整体滚动机制。现在,我们讨论新时间序列的命名约定。
为了识别每个子序列,tsfresh 使用将被预测点的时间戳以及旧标识符作为“id”。对于正向滚动,此 timeshift 是子序列中的最后一个时间戳。对于负向滚动,它是第一个时间戳,例如上面沿负向滚动的 dataframe 会给我们
id |
time |
x |
y |
|---|---|---|---|
(1,1) |
1 |
1 |
5 |
(1,1) |
2 |
2 |
6 |
(1,1) |
3 |
3 |
7 |
(1,1) |
4 |
4 |
8 |
(1,2) |
2 |
2 |
6 |
(1,2) |
3 |
3 |
7 |
(1,2) |
4 |
4 |
8 |
(1,3) |
3 |
3 |
7 |
(1,3) |
4 |
4 |
8 |
(1,4) |
4 |
4 |
8 |
(2,8) |
8 |
10 |
12 |
(2,8) |
9 |
11 |
13 |
(2,9) |
9 |
11 |
13 |
您可以使用未来的时间序列值来预测当前值(如果这在您的情况下有意义)。
选择非默认的 max_timeshift 或 min_timeshift 会使提取的子时间序列变小,甚至完全移除它们(例如,如果 min_timeshift = 1,正向滚动情况下的 (1,1)(即 id=1,timeshift=1)将消失)。使用绝对值较大的 rolling_direction(例如 -2 或 2)将跳过一些窗口(在此情况下,每隔一个窗口)。