特征过滤
特征选择的“所有相关性问题”是指识别所有强相关和弱相关的属性。这个问题对于工业应用中的时间序列分类和回归尤其难以解决,例如预测性维护或生产线优化,因为每个标签或回归目标同时与多个时间序列和元信息相关联。
为了限制不相关特征的数量,tsfresh 采用了 fresh 算法(fresh 是 基于可伸缩假设检验的特征提取 (FeatuRe Extraction based on Scalable Hypothesis tests) 的缩写)[1]。
该算法由 tsfresh.feature_selection.relevance.calculate_relevance_table() 调用。它是一种高效、可扩展的特征提取算法,在机器学习流水线的早期阶段,根据可用特征对分类或回归任务的显著性进行过滤,同时控制所选特征中不相关特征的预期比例。
过滤过程由以下图中描绘的三个阶段组成
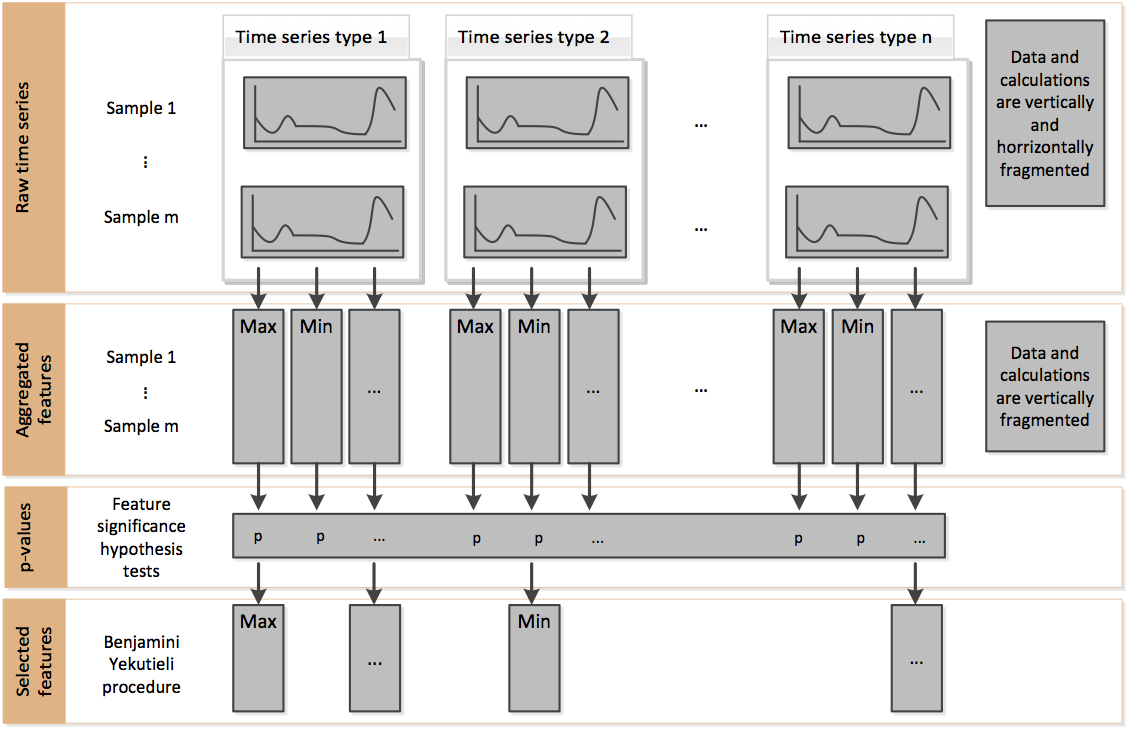
阶段 1 - 特征提取
首先,该算法使用全面且成熟的特征映射来表征时间序列,并考虑描述元信息的附加特征。用于提取这些特征的特征计算器是 tsfresh.feature_extraction.feature_calculators 中的那些。
在上图中,这对应于从原始时间序列到聚合特征的变化。
阶段 2 - 特征显著性检验
第二步,独立评估每个特征向量对于预测研究目标的重要性。这些检验位于子模块 tsfresh.feature_selection.significance_tests 中。这些检验的结果是一个 p 值向量,量化了每个特征对于预测标签/目标的显著性。
在上图中,这对应于从聚合特征到 p 值变化。
阶段 3 - 多重检验过程
基于 Benjamini-Yekutieli 过程 [2] 对 p 值向量进行评估,以决定保留哪些特征。此多重检验过程取自 statsmodel 包。
在上图中,这对应于从 p 值到所选特征的变化。