引言
为何选择 tsfresh?
tsfresh 用于对时间序列和其他顺序数据进行系统性的特征工程 [1]。这些数据的共同之处在于它们按一个独立变量排序。最常见的独立变量是时间(时间序列)。顺序数据的其他例子包括反射和吸收光谱,它们的排序维度是波长。为了简化,我们仅将所有不同类型的顺序数据统称为时间序列。
(是的,天气很冷!)
现在您想计算各种特征,例如最高或最低温度、平均温度或临时温度峰值的数量
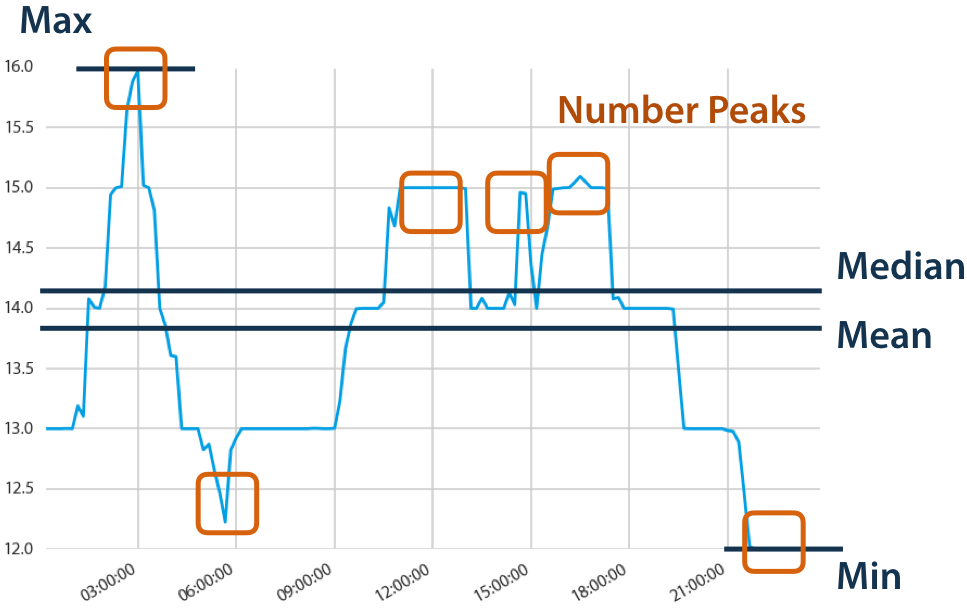
如果没有 tsfresh,您将不得不手动计算所有这些特征;tsfresh 会自动执行此过程,自动计算并返回所有这些特征。
此外,tsfresh 与 Python 库 pandas 和 scikit-learn 兼容,因此您可以轻松地将特征提取集成到当前的例程中。
我们可以用这些特征做什么?
提取的特征可用于描述时间序列,即这些特征通常能提供关于时间序列及其动态的新见解。它们还可用于对时间序列进行聚类,以及训练对时间序列执行分类或回归任务的机器学习模型。
tsfresh 软件包已成功应用于以下项目
tsfresh 不能做什么?
目前,tsfresh 不适用于
流数据(流数据通常用于在线操作,而时间序列数据通常用于离线操作)
对提取的特征训练模型(我们不想重复造轮子,要训练机器学习模型请查看 Python 软件包 scikit-learn)
处理高度不规则的时间序列;tsfresh 仅使用时间戳来排序观测值,而许多特征与间隔无关(例如,峰值数量),可以针对任何序列确定,其他一些特征(例如,线性趋势)假设时间间隔相等,因此当不满足此假设时应谨慎使用。
然而,其中一些用例是可以实现的,如果您有想法的应用,请在 https://github.com/blue-yonder/tsfresh/issues 上开启一个 Issue,或者随时联系我们。
还有哪些类似工具?
有一个名为 hctsa 的 matlab 软件包,可用于自动从时间序列中提取特征。也可以通过 pyopy 软件包在 Python 中使用 hctsa。其他可用的软件包包括 featuretools、FATS 和 cesium。