tsfresh.feature_selection 包
子模块
tsfresh.feature_selection.relevance 模块
包含一种特征选择方法,该方法评估不同提取特征的重要性。为此,对每个特征通过单变量检验评估其对目标的影响,并计算 p 值。计算 p 值的方法称为特征选择器。
然后,Benjamini Hochberg 程序(一种多重检验程序)根据 p 值决定保留哪些特征以及剔除哪些特征。
- tsfresh.feature_selection.relevance.calculate_relevance_table(X, y, ml_task='auto', multiclass=False, n_significant=1, n_jobs=1, show_warnings=False, chunksize=None, test_for_binary_target_binary_feature='fisher', test_for_binary_target_real_feature='mann', test_for_real_target_binary_feature='mann', test_for_real_target_real_feature='kendall', fdr_level=0.05, hypotheses_independent=False)
计算特征矩阵 X 中特征相对于目标向量 y 的相关性表。该相关性表是根据预期的机器学习任务 ml_task 计算的。
为此,对输入 pandas.DataFrame 中的每个特征执行单变量特征显著性检验。这些检验生成 p 值,然后通过 Benjamini Hochberg 程序评估这些 p 值,以决定保留哪些特征以及删除哪些特征。
我们检验
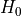 = 该特征不相关,不应添加
= 该特征不相关,不应添加对照
 = 该特征相关,应保留
= 该特征相关,应保留换句话说
= 目标与特征相互独立 / 该特征对目标没有影响 = 目标与特征关联 / 相关当目标是二分类时,这变为
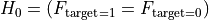
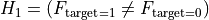
其中
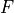 是目标的分布。
是目标的分布。同样,当特征是二分类时,我们可以陈述假设
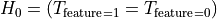
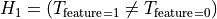
这里
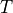 是目标的分布。
是目标的分布。TODO: 那么对于实数值呢?
- 参数:
X (pandas.DataFrame) – 特征矩阵,格式如前所述,将仅保留相关特征。可同时包含二分类和实数值特征。
y (pandas.Series 或 numpy.ndarray) – 目标向量,用于检验哪些特征是相关的。可以是二分类或实数值。
ml_task (str) – 预期的机器学习任务。可以是 ‘classification’ (分类)、‘regression’ (回归) 或 ‘auto’ (自动)。默认为 ‘auto’,表示根据 y 推断预期任务。如果 y 具有布尔、整数或对象 dtype,则假定任务是分类;否则为回归。
multiclass (bool) – 问题是否为多分类。这会改变特征选择的方式。多分类要求特征对于预测 n_significant 个类别具有统计显著性。
n_significant (int) – 特征应具有统计显著性预测能力的类别数量,以被视为“相关”特征
test_for_binary_target_binary_feature (str) – 二分类目标、二分类特征(当前未使用)使用的检验方法
test_for_binary_target_real_feature (str) – 二分类目标、实数值特征使用的检验方法
test_for_real_target_binary_feature (str) – 实数值目标、二分类特征(当前未使用)使用的检验方法
test_for_real_target_real_feature (str) – 实数值目标、实数值特征(当前未使用)使用的检验方法
fdr_level (float) – 应遵守的 FDR 水平,这是所有创建特征中不相关特征的理论预期百分比。
hypotheses_independent (bool) – 特征的显著性是否可以假定为独立?通常应设为 False,因为特征从未独立(例如,均值和中位数)
n_jobs (int) – p 值计算期间使用的进程数
show_warnings (bool) – p 值计算期间显示警告(计算器调试所需)。
chunksize (None 或 int) – 提交给工作进程进行并行化的一个块的大小。其中一个块被定义为一个特征的数据。如果将 chunksize 设置为 10,则意味着一个任务是过滤 10 个特征。如果将其设置为 None,则根据分发器,将使用启发式方法寻找最优块大小。如果遇到内存不足异常,可以尝试使用 dask 分发器和更小的 chunksize。
- 返回:
一个 pandas.DataFrame,其中输入 DataFrame X 的每一列作为索引,包含该特定特征的显著性信息。该 DataFrame 包含列:“feature”(特征)、“type”(类型,二分类、实数或常数)、“p_value”(该特征作为 p 值的显著性,越低表示越显著)、“relevant”(如果 Benjamini Hochberg 程序对该特征拒绝了零假设 [该特征不相关],则为 True)。如果问题是 n 个类别的 multiclass,则 DataFrame 将包含 n 个名为“p_value_CLASSID”的列,而不是“p_value”列。CLASSID 在此指 y 中设置的不同值。还将有 n 个名为 relevant_CLASSID 的列,表示该特征是否与该类别相关。
- 返回类型:
pandas.DataFrame
- tsfresh.feature_selection.relevance.combine_relevance_tables(relevance_tables)
将相关性表列表聚合成一个组合的相关性表,汇总 p 值和相关性。
- 参数:
relevance_tables (List[pd.DataFrame]) – 相关性表列表
- 返回:
组合的相关性表
- 返回类型:
pandas.DataFrame
- tsfresh.feature_selection.relevance.get_feature_type(feature_column)
对于给定的特征,确定它是实数、二分类还是常数。这里的二分类表示特征中只出现两个唯一值。
- 参数:
feature_column (pandas.Series) – 特征列
- 返回:
‘constant’(常数)、‘binary’(二分类)或 ‘real’(实数)
- tsfresh.feature_selection.relevance.infer_ml_task(y)
推断要选择的机器学习任务。结果将是 ‘regression’(回归)或 ‘classification’(分类)。如果目标向量仅包含整数类型值或对象,则假定任务是 ‘classification’;否则为 ‘regression’。
- 参数:
y (pandas.Series) – 目标向量 y。
- 返回:
‘classification’ 或 ‘regression’
- 返回类型:
str
tsfresh.feature_selection.selection 模块
本模块包含提取特征的筛选过程。该筛选过程也可用于非时间序列的特征。
- tsfresh.feature_selection.selection.select_features(X, y, test_for_binary_target_binary_feature='fisher', test_for_binary_target_real_feature='mann', test_for_real_target_binary_feature='mann', test_for_real_target_real_feature='kendall', fdr_level=0.05, hypotheses_independent=False, n_jobs=1, show_warnings=False, chunksize=None, ml_task='auto', multiclass=False, n_significant=1)
检查特征矩阵 X 中所有特征(列)的显著性,并返回一个可能已缩减、仅包含相关特征的特征矩阵。
特征矩阵必须是 pandas.DataFrame,格式如下:
索引
feature_1
feature_2
…
feature_N
A
…
…
…
…
B
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
每一列都将被视为一个特征,并检验其对目标的显著性。
目标向量必须是 pandas.Series 或 numpy.array,形式如下:
索引
目标
A
…
B
…
.
…
.
…
并且必须包含特征矩阵中的所有 id。如果 y 是没有索引的 numpy.array,则假定 y 与 X 具有相同的顺序和长度,并且行相互对应。
示例
>>> from tsfresh.examples import load_robot_execution_failures >>> from tsfresh import extract_features, select_features >>> df, y = load_robot_execution_failures() >>> X_extracted = extract_features(df, column_id='id', column_sort='time') >>> X_selected = select_features(X_extracted, y)
- 参数:
X (pandas.DataFrame) – 特征矩阵,格式如前所述,将仅保留相关特征。可同时包含二分类和实数值特征。
y (pandas.Series 或 numpy.ndarray) – 目标向量,用于检验哪些特征是相关的。可以是二分类或实数值。
test_for_binary_target_binary_feature (str) – 二分类目标、二分类特征(当前未使用)使用的检验方法
test_for_binary_target_real_feature (str) – 二分类目标、实数值特征使用的检验方法
test_for_real_target_binary_feature (str) – 实数值目标、二分类特征(当前未使用)使用的检验方法
test_for_real_target_real_feature (str) – 实数值目标、实数值特征(当前未使用)使用的检验方法
fdr_level (float) – 应遵守的 FDR 水平,这是所有创建特征中不相关特征的理论预期百分比。
hypotheses_independent (bool) – 特征的显著性是否可以假定为独立?通常应设为 False,因为特征从未独立(例如,均值和中位数)
n_jobs (int) – p 值计算期间使用的进程数
show_warnings (bool) – p 值计算期间显示警告(计算器调试所需)。
chunksize (None 或 int) – 提交给工作进程进行并行化的一个块的大小。其中一个块被定义为一个特征的数据。如果将 chunksize 设置为 10,则意味着一个任务是过滤 10 个特征。如果将其设置为 None,则根据分发器,将使用启发式方法寻找最优块大小。如果遇到内存不足异常,可以尝试使用 dask 分发器和更小的 chunksize。
ml_task (str) – 预期的机器学习任务。可以是 ‘classification’ (分类)、‘regression’ (回归) 或 ‘auto’ (自动)。默认为 ‘auto’,表示根据 y 推断预期任务。如果 y 具有布尔、整数或对象 dtype,则假定任务是分类;否则为回归。
multiclass (bool) – 问题是否为多分类。这会改变特征选择的方式。多分类要求特征对于预测 n_significant 个特征具有统计显著性。
n_significant (int) – 特征应具有统计显著性预测能力的类别数量,以被视为“相关”。仅在 multiclass=True 时指定
- 返回:
与 X 相同的 DataFrame,但列数(=特征数)可能已减少。
- 返回类型:
pandas.DataFrame
- 抛出异常:
ValueError当目标向量与特征矩阵不匹配或 ml_task 不是 ‘auto’、‘classification’ 或 ‘regression’ 中的一个时。
tsfresh.feature_selection.significance_tests 模块
包含以下关于 FRESH 算法的论文中的方法 [2]
Fresh 基于假设检验,该检验单独检查每个生成特征对目标的显著性。它确保只保留与当前的回归或分类任务相关的特征。Fresh 根据特征和目标是否为二分类来决定四种设置。
这四个函数名为
target_binary_feature_binary_test():目标和特征均为二分类target_binary_feature_real_test():目标是二分类,特征是实数target_real_feature_binary_test():目标是实数,特征是二分类target_real_feature_real_test():目标和特征均为实数
参考文献
- tsfresh.feature_selection.significance_tests.target_binary_feature_binary_test(x, y)
计算二分类特征与二分类目标的特征显著性,得到 p 值。使用
fisher_exact()的双侧单变量 Fisher 检验。- 参数:
x (pandas.Series) – 二分类特征向量
y (pandas.Series) – 二分类目标向量
- 返回:
特征显著性检验的 p 值。p 值越低表示特征显著性越高
- 返回类型:
float
- 抛出异常:
ValueError如果目标或特征不是二分类。
- tsfresh.feature_selection.significance_tests.target_binary_feature_real_test(x, y, test)
计算实数值特征与二分类目标的特征显著性,得到 p 值。为此,使用
mannwhitneyu()的 Mann-Whitney U 检验 或ks_2samp()的 Kolmogorov Smirnov 检验。- 参数:
x (pandas.Series) – 实数值特征向量
y (pandas.Series) – 二分类目标向量
test (str) – 要使用的显著性检验。对于 Mann-Whitney-U 检验使用
'mann',对于 Kolmogorov-Smirnov 检验使用'smir'
- 返回:
特征显著性检验的 p 值。p 值越低表示特征显著性越高
- 返回类型:
float
- 抛出异常:
ValueError如果目标不是二分类。
- tsfresh.feature_selection.significance_tests.target_real_feature_binary_test(x, y)
计算二分类特征与实数值目标的特征显著性,得到 p 值。为此,使用
ks_2samp()的 Kolmogorov-Smirnov 检验。- 参数:
x (pandas.Series) – 二分类特征向量
y (pandas.Series) – 实数值目标向量
- 返回:
特征显著性检验的 p 值。p 值越低表示特征显著性越高。
- 返回类型:
float
- 抛出异常:
ValueError如果特征不是二分类。
- tsfresh.feature_selection.significance_tests.target_real_feature_real_test(x, y)
计算实数值特征与实数值目标的特征显著性,得到 p 值。为此,使用
kendalltau()的 Kendall’s tau。- 参数:
x (pandas.Series) – 实数值特征向量
y (pandas.Series) – 实数值目标向量
- 返回:
特征显著性检验的 p 值。p 值越低表示特征显著性越高。
- 返回类型:
float
模块内容
feature_selection 模块包含特征选择算法。这些方法适用于从大量特征中挑选出解释性最好的特征。通常,在特征多于样本的情况下需要挑选特征。传统的特征选择方法可能不适合这种情况,因此我们提出一种基于 p 值的方法,该方法单独检查特征的显著性,以避免过拟合和虚假相关性。