tsfresh.feature_extraction 包
子模块
tsfresh.feature_extraction.data 模块
- class tsfresh.feature_extraction.data.DaskTsAdapter(df, column_id, column_kind=None, column_value=None, column_sort=None)[source]
基类:
TsData
- class tsfresh.feature_extraction.data.LongTsFrameAdapter(df, column_id, column_kind, column_value=None, column_sort=None)[source]
- class tsfresh.feature_extraction.data.PartitionedTsData(df, column_id)[source]
基类:
Iterable[Timeseries],Sized,TsDataTsData 的特殊类,可以进行分区。派生类应实现 __iter__ 和 __len__ 方法。
- class tsfresh.feature_extraction.data.Timeseries(id, kind, data)[source]
基类:
Timeseries用于特征提取的时间序列元组。
确保 kind 的类型为 str,以便在 feature_extraction.settings.from_columns 中推断特征设置。
- class tsfresh.feature_extraction.data.TsData[source]
基类:
objectTsData 为内部使用提供时间序列数据的访问。
分发器将使用此数据类来对数据应用函数。所有派生类必须实现 apply 方法(用于直接对数据应用给定函数)或 __iter__ 方法(用于获取 Timeseries 实例的迭代器,分发器可用于此迭代器应用函数)。如果底层数据存储存在更有效的解决方案,则可以覆盖其他方法。
- class tsfresh.feature_extraction.data.TsDictAdapter(ts_dict, column_id, column_value, column_sort=None)[source]
- class tsfresh.feature_extraction.data.WideTsFrameAdapter(df, column_id, column_sort=None, value_columns=None)[source]
- tsfresh.feature_extraction.data.to_tsdata(df, column_id=None, column_kind=None, column_value=None, column_sort=None)[source]
将支持的数据格式包装为 TsData 对象,即一个包含单个时间序列的可迭代对象。
例如,将 DataFrame
id
kind
val
1
a
-0.21761
1
a
-0.613667
1
a
-2.07339
2
b
-0.576254
2
b
-1.21924
转换为
- Iterable((1, ‘a’, pd.Series([-0.217610, -0.613667, -2.073386]),
(2, ‘b’, pd.Series([-0.576254, -1.219238]))
tsfresh.feature_extraction.extraction 模块
此模块包含与 tsfresh 交互的主要函数:提取特征
- tsfresh.feature_extraction.extraction.extract_features(timeseries_container, default_fc_parameters=None, kind_to_fc_parameters=None, column_id=None, column_sort=None, column_kind=None, column_value=None, chunksize=None, n_jobs=1, show_warnings=False, disable_progressbar=False, impute_function=None, profile=False, profiling_filename='profile.txt', profiling_sorting='cumulative', distributor=None, pivot=True)[source]
从以下对象中提取特征:
包含不同时间序列的
pandas.DataFrame
或
一个字典,其中每个
pandas.DataFrame包含一种类型的时间序列
在这两种情况下,都将返回一个包含计算特征的
pandas.DataFrame。有关所有计算的时间序列特征列表,请参阅
ComprehensiveFCParameters类,该类用于控制计算哪些特征及其参数。有关不同参数(例如列)和数据格式的详细说明,请参阅 数据格式。
示例
>>> from tsfresh.examples import load_robot_execution_failures >>> from tsfresh import extract_features >>> df, _ = load_robot_execution_failures() >>> X = extract_features(df, column_id='id', column_sort='time')
- 参数:
timeseries_container (pandas.DataFrame 或 dict) – 包含需要计算特征的时间序列的 pandas.DataFrame,或一个 pandas.DataFrame 字典。
default_fc_parameters (dict) – 特征计算器名称到参数的映射。只会计算此字典中作为键的特征名称。有关更多信息,请参阅 ComprehensiveFCParameters 类。
kind_to_fc_parameters (dict) – 种类名称到与 default_fc_parameters 相同类型对象的映射。如果在此处将一种种类作为键,则将使用 fc_parameters 对象(即其对应的值),而不是 default_fc_parameters。这意味着对于 kind_of_fc_parameters 中没有任何条目的种类,特征选择将忽略它们。
column_id (str) – 用于分组的 id 列的名称。请参阅 数据格式。
column_sort (str) – 排序列的名称。请参阅 数据格式。
column_kind (str) – 记录值类型的列的名称。请参阅 数据格式。
column_value (str) – 保存值本身的列的名称。请参阅 数据格式。
n_jobs (int) – 用于并行化的进程数。如果为零,则不使用并行化。
chunksize (None 或 int) – 提交给工作进程进行并行化的一个块的大小。一个块被定义为单个 id 和一种类型的单个时间序列。如果将 chunksize 设置为 10,则意味着一个任务是计算 10 个时间序列的所有特征。如果设置为 None,则根据分发器,使用启发式方法找到最优的 chunksize。如果遇到内存不足异常,可以尝试使用 dask 分发器和较小的 chunksize。
show_warnings (bool) – 在特征提取过程中显示警告(计算器调试需要)。
disable_progressbar (bool) – 在计算时不显示进度条。
impute_function (None 或 callable) – 如果不进行插补则为 None,否则为用于插补结果 DataFrame 的函数。插补永远不会发生在输入数据上。
profile (bool) – 在特征提取期间开启性能分析
profiling_sorting (basestring) – 如何对性能分析结果进行排序(有关更多信息,请参阅性能分析包的文档)
profiling_filename (basestring) – 保存性能分析结果的文件名。
distributor (class) – 高级参数:将其设置为要用作分发器的类名。有关更多信息,请参阅 utilities/distribution.py。如果希望 TSFresh 选择最佳分发器,则留空 None。
- 返回:
包含提取特征的(可能已插补的)DataFrame。
- 返回类型:
pandas.DataFrame
tsfresh.feature_extraction.feature_calculators 模块
此模块包含以时间序列为输入并计算特征值的特征计算器。特征分为两种类型:
计算单个数值的特征计算器(简单)
一次为一组参数计算大量特征的特征计算器,例如使用缓存结果(组合器)。它们为每个输入参数返回一个 (key, value) 对列表。
它们使用每个特征计算器的“fctype”参数指定,该参数通过 set_property 函数添加。只有此 Python 模块中具有名为“fctype”参数的函数才被 tsfresh 视为特征计算器。其他函数不会被计算。
组合器类型的特征计算器应返回按字母升序排序的连接参数。
- tsfresh.feature_extraction.feature_calculators.abs_energy(x)[source]
返回时间序列的绝对能量,即平方值的总和
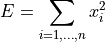
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.absolute_maximum(x)[source]
计算时间序列 x 的最高绝对值。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.absolute_sum_of_changes(x)[source]
返回序列 x 中连续变化绝对值的总和
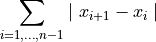
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.agg_autocorrelation(x, param)[source]
时间序列自相关的描述性统计量。
计算不同滞后下自相关函数
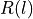 的聚合函数
的聚合函数 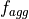 (例如方差或均值) 的值。滞后
(例如方差或均值) 的值。滞后 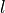 的自相关函数 定义为
的自相关函数 定义为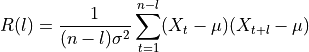
其中
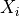 是时间序列的值,
是时间序列的值,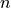 是其长度。最后,
是其长度。最后,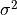 和
和 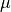 是其方差和均值的估计量(参见 自相关函数估计)。
是其方差和均值的估计量(参见 自相关函数估计)。不同滞后
的 形成一个向量。此特征计算器将聚合函数 应用于此向量并返回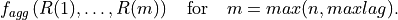
这里
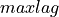 是传递给此函数的第二个参数。
是传递给此函数的第二个参数。- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
param (list) – 包含字典 {“f_agg”: x, “maxlag”, n},其中 x 是字符串,一个 numpy 函数的名称(例如“mean”、“var”、“std”、“median”),它是应用于自相关函数的聚合器函数的名称。此外,n 是一个整数,表示考虑的最大滞后数。
- 返回:
此特征的值
- 返回类型:
List[Tuple[str, float]]
此函数的类型为:combiner
- tsfresh.feature_extraction.feature_calculators.agg_linear_trend(x, param)[source]
计算时间序列值(按块聚合)对块编号(从 0 到块数减一)的线性最小二乘回归。
此特征假设信号均匀采样。它不会使用时间戳来拟合模型。
参数 attr 控制返回哪些特征。可能的提取属性有“pvalue”、“rvalue”、“intercept”、“slope”、“stderr”,更多信息请参阅 linregress 的文档。
块大小由“chunk_len”控制。它指定每个块中包含多少个时间序列值。
此外,聚合函数由“f_agg”控制,可以使用“max”、“min”或“mean”、“median”。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
param (list) – 包含字典 {“attr”: x, “chunk_len”: l, “f_agg”: f},其中 x, f 为字符串,l 为整数。
- 返回:
不同的特征值
- 返回类型:
Iterator[Tuple[str, float]]
此函数的类型为:combiner
- tsfresh.feature_extraction.feature_calculators.approximate_entropy(x, m, r)[source]
实现向量化近似熵算法。
对于短时间序列,此方法高度依赖于参数,但对于 N > 2000 应稳定,参见
Yentes 等人 (2012) - 近似熵和样本熵在短数据集上的适当使用
讨论的其他缺点和替代方案
Richman & Moorman (2000) - 使用近似熵和样本熵的生理时间序列分析
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
m (int) – 比较数据运行的长度
r (float) – 过滤级别,必须为正
- 返回:
近似熵
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.ar_coefficient(x, param)[source]
此特征计算器拟合自回归 AR(k) 过程的无条件最大似然估计。参数 k 是过程的最大滞后。
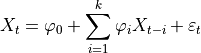
对于 param 中的配置(应包含最大滞后“k”),计算相应的 AR 过程。然后返回索引
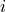 在“coeff”中包含的系数
在“coeff”中包含的系数 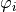 。
。- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
param (list) – 包含字典 {“coeff”: x, “k”: y},其中 x, y 为整数。
- 返回 x:
不同的特征值
- 返回类型:
List[Tuple[str, float]]
此函数的类型为:combiner
- tsfresh.feature_extraction.feature_calculators.augmented_dickey_fuller(x, param)[source]
时间序列是否具有单位根?
增广迪基-福勒检验(Augmented Dickey-Fuller test)是一种假设检验,用于检查时间序列样本中是否存在单位根。此特征计算器返回相应检验统计量的值。
有关参考资料和更多详细信息,请参阅 statsmodels 的实现。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
param (list) – 包含字典 {“attr”: x, “autolag”: y},其中 x 是字符串,可以是“teststat”、“pvalue”或“usedlag”,y 是字符串,可以是“AIC”、“BIC”、“t-stats”或 None(参见 statsmodels 中 adfuller() 的文档)。
- 返回:
此特征的值
- 返回类型:
List[Tuple[str, float]]
此函数的类型为:combiner
- tsfresh.feature_extraction.feature_calculators.autocorrelation(x, lag)[source]
根据公式 [1] 计算指定滞后的自相关
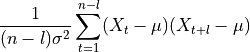
其中
是时间序列 的长度, 是其方差, 是其均值。l 表示滞后。参考资料
[1] https://en.wikipedia.org/wiki/Autocorrelation#Estimation
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
lag (int) – 滞后
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.benford_correlation(x)[source]
对于异常检测应用很有用 [1][2]。当与纽康-本福特定律分布 [3][4] 比较时,返回首位数字分布的关联度。
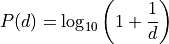
其中
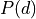 是
是  的纽康-本福特分布, 是数字 {1, 2, 3, 4, 5, 6, 7, 8, 9} 的首位数字。
的纽康-本福特分布, 是数字 {1, 2, 3, 4, 5, 6, 7, 8, 9} 的首位数字。参考资料
[1] A Statistical Derivation of the Significant-Digit Law, Theodore P. Hill, Statistical Science, 1995[2] The significant-digit phenomenon, Theodore P. Hill, The American Mathematical Monthly, 1995[3] The law of anomalous numbers, Frank Benford, Proceedings of the American philosophical society, 1938[4] Note on the frequency of use of the different digits in natural numbers, Simon Newcomb, American Journal ofmathematics, 1881- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.binned_entropy(x, max_bins)[source]
首先将 x 的值分成 max_bins 个等距区间。然后计算以下值:
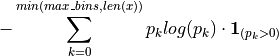
其中
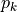 是区间
是区间 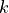 中样本的百分比。
中样本的百分比。- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
max_bins (int) – 最大区间数
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.c3(x, lag)[source]
使用 c3 统计量测量时间序列的非线性
此函数计算以下值:
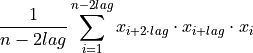
即
![\mathbb{E}[L^2(X) \cdot L(X) \cdot X]](../_images/math/352e21198896f6a218bb7e5fb4ab4fabc89b3669.png)
其中
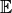 是均值,
是均值,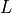 是滞后算子。它在 [1] 中被提出作为衡量时间序列非线性的指标。
是滞后算子。它在 [1] 中被提出作为衡量时间序列非线性的指标。参考资料
[1] Schreiber, T. and Schmitz, A. (1997).Discrimination power of measures for nonlinearity in a time seriesPHYSICAL REVIEW E, VOLUME 55, NUMBER 5- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
lag (int) – 计算特征时应使用的滞后
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.change_quantiles(x, ql, qh, isabs, f_agg)[source]
首先根据 x 分布的分位数 ql 和 qh 确定一个区间。然后计算此区间内序列 x 连续变化的平均绝对值。
考虑在 y 轴上选择一个区间,只计算时间序列在此区间内的绝对变化的均值。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
ql (float) – 区间的下分位数
qh (float) – 区间的上分位数
isabs (bool) – 是否应取绝对差值?
f_agg (str, 一个 numpy 函数的名称 (例如 mean, var, std, median)) – 应用于区间内差值的聚合函数
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.cid_ce(x, normalize)[source]
此函数计算器是时间序列复杂度 [1] 的估计值(更复杂的时间序列具有更多峰值、谷值等)。它计算以下值:
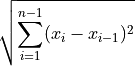
参考资料
[1] Batista, Gustavo EAPA, et al (2014).CID: an efficient complexity-invariant distance for time series.Data Mining and Knowledge Discovery 28.3 (2014): 634-669.- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
normalize (bool) – 时间序列是否应进行 z 变换?
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.count_above(x, t)[source]
返回 x 中高于 t 的值的百分比
- 参数:
x (pandas.Series) – 用于计算特征的时间序列
t (float) – 用作阈值的值
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.count_above_mean(x)[source]
返回 x 中高于 x 平均值的数量
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.count_below(x, t)[source]
返回 x 中低于 t 的值的百分比
- 参数:
x (pandas.Series) – 用于计算特征的时间序列
t (float) – 用作阈值的值
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.count_below_mean(x)[source]
返回 x 中低于 x 平均值的数量
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.cwt_coefficients(x, param)[source]
计算 Ricker 小波的连续小波变换,也称为“墨西哥帽小波”,其定义为
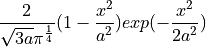
其中
 是小波函数的宽度参数。
是小波函数的宽度参数。此特征计算器接受三个不同的参数:widths、coeff 和 w。特征计算器获取所有不同的 widths 数组,然后为每个不同的 width 数组计算一次 cwt。然后返回针对 coeff 和宽度 w 的不同系数的值。(对于 param 中的每个字典,返回一个特征)
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
param (list) – 包含字典 {“widths”:x, “coeff”: y, “w”: z},其中 x 是整数数组,y, z 是整数。
- 返回:
不同的特征值
- 返回类型:
Iterator[Tuple[str, float]]
此函数的类型为:combiner
- tsfresh.feature_extraction.feature_calculators.energy_ratio_by_chunks(x, param)[source]
计算 N 个块中块 i 的平方和,表示为整个序列平方和的比例。
接受的输入参数是将序列分割成的段数 num_segments 和 segment_focus(从零开始的段号),用于返回特征。
如果时间序列的长度不是段数的倍数,则剩余数据点将从第一个区间开始分布。例如,如果您的时间序列包含 8 个条目,则前两个区间将包含 3 个值,后两个区间包含剩余值,例如 [ 0., 1., 2.], [ 3., 4., 5.] 和 [ 6., 7.]。
注意,对于 num_segments = 1 的结果是微不足道的“1”,但我们仍然处理这种情况,以防有人调用它。比例总和应为 1.0。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
param – 包含字典 {“num_segments”: N, “segment_focus”: i},其中 N, i 均为整数。
- 返回:
特征值
- 返回类型:
List[Tuple[str, float]]
此函数的类型为:combiner
- tsfresh.feature_extraction.feature_calculators.fft_aggregated(x, param)[source]
返回绝对傅里叶变换谱的谱质心(均值)、方差、偏度和峰度。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
param (list) – 包含字典 {“aggtype”: s},其中 s 为字符串,且在 [“centroid”, “variance”, “skew”, “kurtosis”] 中。
- 返回:
不同的特征值
- 返回类型:
Iterator[Tuple[str, float]]
此函数的类型为:combiner
- tsfresh.feature_extraction.feature_calculators.fft_coefficient(x, param)[source]
通过快速傅里叶变换算法计算实数输入的一维离散傅里叶变换的傅里叶系数
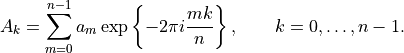
结果系数将是复数,此特征计算器可以返回实部 (attr==”real”)、虚部 (attr==”imag”)、绝对值 (attr==”abs”) 和角度(度)(attr==”angle”)。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
param (list) – 包含字典 {“coeff”: x, “attr”: s},其中 x 为整数且 x >= 0,s 为字符串且在 [“real”, “imag”, “abs”, “angle”] 中。
- 返回:
不同的特征值
- 返回类型:
Iterator[Tuple[str, float]]
此函数的类型为:combiner
- tsfresh.feature_extraction.feature_calculators.first_location_of_maximum(x)[source]
返回 x 最大值的第一个位置。位置是相对于 x 的长度计算的。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.first_location_of_minimum(x)[source]
返回 x 最小值的第一个位置。位置是相对于 x 的长度计算的。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.fourier_entropy(x, bins)[source]
计算时间序列功率谱密度(使用 Welch 方法)的区间熵。
参考:https://hackaday.io/project/707-complexity-of-a-time-series/details 参考:https://docs.scipy.org.cn/doc/scipy-0.14.0/reference/generated/scipy.signal.welch.html
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.friedrich_coefficients(x, param)[source]
多项式
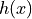 的系数,该多项式已拟合到 Langevin 模型的确定性动力学
的系数,该多项式已拟合到 Langevin 模型的确定性动力学
如 [1] 中所述。
对于短时间序列,此方法高度依赖于参数。
参考资料
[1] Friedrich 等人 (2000): Physics Letters A 271, p. 217-222Extracting model equations from experimental data- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
param (list) – 包含字典 {“m”: x, “r”: y, “coeff”: z},其中 x 是正整数,表示用于估计动力学不动点的多项式阶数;y 是正浮点数,表示用于平均的分位数数量;最后 z 是正整数,对应于返回的系数。
- 返回:
不同的特征值
- 返回类型:
List[Tuple[str, float]]
此函数的类型为:combiner
- tsfresh.feature_extraction.feature_calculators.has_duplicate(x)[source]
检查 x 中是否有任何值出现多次
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
bool
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.has_duplicate_max(x)[source]
检查 x 的最大值是否出现多次
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
bool
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.has_duplicate_min(x)[source]
检查 x 的最小值是否出现多次
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
bool
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.index_mass_quantile(x, param)[source]
计算时间序列 x 中相对索引 i,其中 x 的质量的 q% 位于 i 的左侧。例如,对于 q = 50%,此特征计算器将返回时间序列的质量中心。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
param (list) – 包含字典 {“q”: x},其中 x 为浮点数。
- 返回:
不同的特征值
- 返回类型:
List[Tuple[str, float]]
此函数的类型为:combiner
- tsfresh.feature_extraction.feature_calculators.kurtosis(x)[source]
返回 x 的峰度(使用调整后的 Fisher-Pearson 标准化矩系数 G2 计算)。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.large_standard_deviation(x, r)[source]
时间序列的标准差是否 大?
布尔变量,表示 x 的标准差是否高于 x 的范围(最大值与最小值之差)的 ‘r’ 倍。因此它检查是否
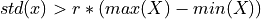
根据经验法则,标准差应为值范围的四分之一。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
r (float) – 用于比较的范围百分比
- 返回:
此特征的值
- 返回类型:
bool
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.last_location_of_maximum(x)[source]
返回 x 最大值的相对最后位置。位置是相对于 x 的长度计算的。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.last_location_of_minimum(x)[source]
返回 x 最小值的最后位置。位置是相对于 x 的长度计算的。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.lempel_ziv_complexity(x, bins)[source]
基于 Lempel-Ziv 压缩算法计算复杂度估计值。
复杂度定义为从左到右查看时编码时间序列所需的字典条目(或子词)数量。为此,首先将时间序列分入给定的区间数。然后将其转换为具有不同前缀的子词。所需的子词数量除以时间序列的长度就是复杂度估计值。
例如,如果时间序列(仅分入 2 个区间后)看起来像“100111”,则不同的子词将是 1、0、01 和 11,因此结果是 4/6 = 0.66。
参考:https://github.com/Naereen/Lempel-Ziv_Complexity/blob/master/src/lempel_ziv_complexity.py
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.length(x)[source]
返回 x 的长度
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
int
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.linear_trend(x, param)[source]
计算时间序列值对序列(从 0 到时间序列长度减一)的线性最小二乘回归。此特征假设信号均匀采样。它不会使用时间戳来拟合模型。参数控制返回哪些特征。
可能的提取属性包括“pvalue”、“rvalue”、“intercept”、“slope”、“stderr”,有关更多信息请参阅 linregress 的文档。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
param (list) – 包含字典 {“attr”: x},其中 x 是字符串,表示回归模型的属性名称。
- 返回:
不同的特征值
- 返回类型:
List[Tuple[str, float]]
此函数的类型为:combiner
- tsfresh.feature_extraction.feature_calculators.linear_trend_timewise(x, param)[source]
计算时间序列值对序列(从 0 到时间序列长度减一)的线性最小二乘回归。此特征使用时间序列的索引来拟合模型,索引必须是 datetime 类型。参数控制返回哪些特征。
可能的提取属性包括“pvalue”、“rvalue”、“intercept”、“slope”、“stderr”,有关更多信息请参阅 linregress 的文档。
- 参数:
x (pandas.Series) – 用于计算特征的时间序列。索引必须是 datetime 类型。
param (list) – 包含字典 {“attr”: x},其中 x 是字符串,表示回归模型的属性名称。
- 返回:
不同的特征值
- 返回类型:
List[Tuple[str, float]]
此函数的类型为:combiner
- tsfresh.feature_extraction.feature_calculators.longest_strike_above_mean(x)[source]
返回 x 中连续子序列长度最长且大于 x 平均值的子序列长度
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.longest_strike_below_mean(x)[source]
返回 x 中连续子序列长度最长且小于 x 平均值的子序列长度
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.matrix_profile(x, param)[source]
计算一维矩阵剖面 [1],并返回 Tukey 的五数集以及该矩阵剖面的均值。
此特征不再受支持,因为 matrixprofile 未与最新的 Python 版本同步。要使用它,可以使用 pip install tsfresh[matrixprofile] 安装额外依赖。
参考资料
[1] Yeh 等人 (2016), IEEE ICDM- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
param (list) – 包含字典 {“sample_pct”: x, “threshold”: y, “feature”: z},其中 sample_pct 和 threshold 是 matrixprofile 包的参数 https://matrixprofile.docs.matrixprofile.org/api.html#matrixprofile-compute,feature 是“min”、“max”、“mean”、“median”、“25”、“75”之一,用于决定提取矩阵剖面的哪个特征。
- 返回:
不同的特征值
- 返回类型:
List[Tuple[str, float]]
此函数的类型为:combiner
- tsfresh.feature_extraction.feature_calculators.max_langevin_fixed_point(x, r, m)[source]
动力学的最大不动点 :math:argmax_x {h(x)=0}`,从多项式
估计,该多项式已拟合到 Langevin 模型的确定性动力学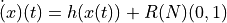
如以下文献所述
Friedrich 等人 (2000): Physics Letters A 271, p. 217-222 从实验数据中提取模型方程
对于短时间序列,此方法高度依赖于参数。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
m (int) – 用于估计动力学不动点的多项式拟合阶数
r (float) – 用于平均的分位数数量
- 返回:
确定性动力学的最大不动点
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.maximum(x)[source]
计算时间序列 x 的最高值。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.mean(x)[source]
返回 x 的均值
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.mean_abs_change(x)[source]
一阶差分的平均值。
返回连续时间序列值绝对差的均值,即
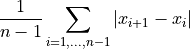
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.mean_change(x)[source]
时间序列差分的平均值。
返回连续时间序列值差的均值,即
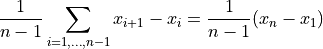
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.mean_n_absolute_max(x, number_of_maxima)[source]
计算时间序列的 n 个绝对最大值的算术平均值。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
number_of_maxima (int) – 应考虑的最大值数量
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.mean_second_derivative_central(x)[source]
返回中心近似二阶导数的平均值

- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.median(x)[source]
返回 x 的中位数
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.minimum(x)[source]
计算时间序列 x 的最低值。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.number_crossing_m(x, m)[source]
计算时间序列 x 在阈值 m 上的交叉次数。交叉定义为两个连续值,其中第一个值低于 m 且下一个值高于 m,反之亦然。如果将 m 设为零,则将获得零交叉的次数。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
m (float) – 交叉的阈值
- 返回:
此特征的值
- 返回类型:
int
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.number_cwt_peaks(x, n)[source]
x 中不同峰值的数量。
为了估计峰值数量,x 通过宽度范围从 1 到 n 的 Ricker 小波进行平滑。此特征计算器返回在足够宽度尺度和足够高的信噪比(SNR)下出现的峰值数量。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
n (int) – 考虑的最大宽度
- 返回:
此特征的值
- 返回类型:
int
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.number_peaks(x, n)[source]
计算时间序列 x 中至少具有支持度 n 的峰值数量。支持度 n 的峰值定义为 x 的一个子序列,其中某个值出现,并且该值大于其左侧和右侧的 n 个邻居。
因此在序列中
>>> x = [3, 0, 0, 4, 0, 0, 13]
4 is a peak of support 1 and 2 because in the subsequences
>>> [0, 4, 0] >>> [0, 0, 4, 0, 0]
4 仍然是最高值。在这里,4 不是支持度 3 的峰值,因为 13 是 4 右侧的第 3 个邻居,并且它比 4 大。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
n (int) – 峰值的支持度
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.partial_autocorrelation(x, param)[source]
计算给定滞后下的偏自相关函数值。
时间序列
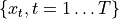 在滞后 k 处的偏自相关等于
在滞后 k 处的偏自相关等于  和
和 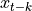 的偏相关,并根据中间变量
的偏相关,并根据中间变量 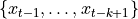 进行调整 ([1])。
进行调整 ([1])。根据 [2],它可以定义为
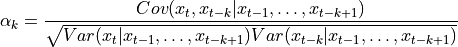
其中 (a)
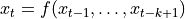 和 (b)
和 (b)  是可以通过 OLS 拟合的 AR(k-1) 模型。请注意,在 (a) 中,回归是根据过去值来预测 ,而在 (b) 中,使用未来值来计算过去值 。在 [1] 中提到,“对于 AR(p),偏自相关 [
是可以通过 OLS 拟合的 AR(k-1) 模型。请注意,在 (a) 中,回归是根据过去值来预测 ,而在 (b) 中,使用未来值来计算过去值 。在 [1] 中提到,“对于 AR(p),偏自相关 [ 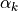 ] 在 k<=p 时非零,在 k>p 时为零。”利用这一特性,它被用于确定 AR 过程的滞后。
] 在 k<=p 时非零,在 k>p 时为零。”利用这一特性,它被用于确定 AR 过程的滞后。参考资料
[1] Box, G. E., Jenkins, G. M., Reinsel, G. C., & Ljung, G. M. (2015).时间序列分析:预测与控制。John Wiley & Sons。- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
param (list) – 包含字典 {“lag”: val},其中 int val 表示要返回的滞后
- 返回:
此特征的值
- 返回类型:
List[Tuple[str, float]]
此函数的类型为:combiner
- tsfresh.feature_extraction.feature_calculators.percentage_of_reoccurring_datapoints_to_all_datapoints(x)[source]
返回非唯一数据点的百分比。非唯一意味着它们在时间序列中再次出现。
出现不止一次的数据点数量 / 所有数据点数量
这意味着该比例已根据时间序列中的数据点数量进行归一化,这与 percentage_of_reoccurring_values_to_all_values 不同。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.percentage_of_reoccurring_values_to_all_values(x)[source]
返回在时间序列中出现不止一次的值的百分比。
出现不止一次的不同值的数量 / 不同值的数量
这意味着该百分比已根据唯一值的数量进行归一化,这与 percentage_of_reoccurring_datapoints_to_all_datapoints 不同。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.permutation_entropy(x, tau, dimension)[source]
计算排列熵。
这需要三个步骤
将数据块分割成长度为 D 的子窗口,每个 tau 间隔开始。按照参考中的例子,向量
x = [4, 7, 9, 10, 6, 11, 3
其中 D = 3 且 tau = 1 转换为
- [[ 4, 7, 9],
[ 7, 9, 10], [ 9, 10, 6], [10, 6, 11], [ 6, 11, 3]]
将每个 D 窗口替换为其反映数据序数排名的排列。结果是
- [[0, 1, 2],
[0, 1, 2], [1, 2, 0], [1, 0, 2], [1, 2, 0]]
现在我们只需要计算每个排列的频率并返回它们的熵(我们使用 log_e 而不是 log_2)。
- 参考: https://www.aptech.com/blog/permutation-entropy/
Bandt, Christoph and Bernd Pompe. “Permutation entropy: a natural complexity measure for time series.” Physical review letters 88 17 (2002): 174102 .
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.quantile(x, q)[source]
计算 x 的 q 分位数。这是 x 中大于 x 中 q% 的有序值的值。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
q (float) – 要计算的分位数
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.query_similarity_count(x, param)[source]
此特征计算器接受输入查询子序列参数,将查询(在 z 归一化欧几里德距离下)与时间序列中的所有子序列进行比较,并返回在时间序列中找到查询的次数计数(在某个预定义的_最大距离阈值内_)。请注意,未提供查询子序列时,此特征将始终返回 np.nan,因此用户需要自行启用此特征。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
param (list[dict]) – 包含字典 {“query”: Q, “threshold”: thr, “normalize”: norm},其中 Q (numpy.ndarray) 是用于与时间序列进行比较的查询子序列。如果省略 Q,则返回零。此外,thr (float) 是用于增加查询相似度计数的最大 z 归一化欧几里德距离阈值。如果省略 thr,则使用默认阈值 thr=0.0,这相当于查找与 Q 的精确匹配。最后,对于非归一化(即未经 z 归一化)的欧几里德距离,将 norm (bool) 设置为 `False。
- 返回 x:
不同的特征值
- 返回类型:
List[Tuple[str, int | np.nan]]
此函数的类型为:combiner
- tsfresh.feature_extraction.feature_calculators.range_count(x, min, max)[source]
计算区间 [min, max) 内的观测值数量。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
min (int or float) – 区间的包含下界
max (int or float) – 区间的排除上界
- 返回:
区间内的值数量
- 返回类型:
int
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.ratio_beyond_r_sigma(x, r)[source]
与 x 的均值相距 r * std(x)(即 r 倍标准差)以上的值的比例。
- 参数:
x (iterable) – 要计算特征的时间序列
r (float) – 用于比较的比例
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.ratio_value_number_to_time_series_length(x)[source]
返回一个因子,如果时间序列中的所有值只出现一次,则该因子为 1;否则小于 1。原则上,它只返回
唯一值的数量 / 值数量
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.root_mean_square(x)[source]
返回时间序列的均方根(rms)。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.sample_entropy(x)[source]
计算并返回 x 的样本熵。
参考资料
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.set_property(key, value)[source]
此方法返回一个装饰器,用于将函数的属性键设置为值
- tsfresh.feature_extraction.feature_calculators.skewness(x)[source]
返回 x 的样本偏度(使用调整后的 Fisher-Pearson 标准化矩系数 G1 计算)。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.spkt_welch_density(x, param)[source]
此特征计算器估计时间序列 x 在不同频率下的交叉功率谱密度。为此,首先将时间序列从时域转换到频域。
特征计算器返回不同频率的功率谱。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
param (list) – 包含字典 {“coeff”: x},其中 x 为 int 类型
- 返回:
不同的特征值
- 返回类型:
Iterator[Tuple[str, float]]
此函数的类型为:combiner
- tsfresh.feature_extraction.feature_calculators.standard_deviation(x)[source]
返回 x 的标准差
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.sum_of_reoccurring_data_points(x)[source]
返回时间序列中出现不止一次的所有数据点之和。
例如
sum_of_reoccurring_data_points([2, 2, 2, 2, 1]) = 8
因为 2 是一个重复出现的值,所以所有 2 都被加起来。
这与
sum_of_reoccurring_values不同,后者中每个重复出现的值只计算一次。- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.sum_of_reoccurring_values(x)[source]
返回时间序列中出现不止一次的所有值之和。
例如
sum_of_reoccurring_values([2, 2, 2, 2, 1]) = 2
因为 2 是一个重复出现的值,所以它与其他所有重复出现的值(没有其他重复值)相加,结果是 2。
这与
sum_of_reoccurring_data_points不同,后者中每个重复出现的值只按其在数据中出现的次数进行计算。- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.sum_values(x)[source]
计算时间序列值的总和
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.symmetry_looking(x, param)[source]
布尔变量,指示 x 的分布是否看起来对称。满足以下条件时为对称:
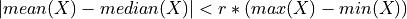
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
param (list) – 包含字典 {“r”: x},其中 x (float) 是用于比较的范围百分比
- 返回:
此特征的值
- 返回类型:
List[Tuple[str, bool]]
此函数的类型为:combiner
- tsfresh.feature_extraction.feature_calculators.time_reversal_asymmetry_statistic(x, lag)[source]
返回时间反转非对称统计量。
此函数计算以下值:
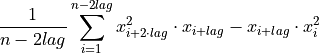
即
![\mathbb{E}[L^2(X)^2 \cdot L(X) - L(X) \cdot X^2]](../_images/math/bfe1cfc74e3ffaf69103b4b966271aa22b14ece0.png)
其中
是均值, 是滞后算子。在 [1] 中,它被提出作为从时间序列中提取的有前途的特征。参考资料
[1] Fulcher, B.D., Jones, N.S. (2014).基于高度比较特征的时间序列分类。Knowledge and Data Engineering, IEEE Transactions on 26, 3026–3037.- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
lag (int) – 计算特征时应使用的滞后
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.value_count(x, value)[source]
计算时间序列 x 中 value 的出现次数。
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
value (int or float) – 要计数的数值
- 返回:
计数结果
- 返回类型:
int
此函数的类型为:simple
- tsfresh.feature_extraction.feature_calculators.variance(x)[source]
返回 x 的方差
- 参数:
x (numpy.ndarray) – 用于计算特征的时间序列
- 返回:
此特征的值
- 返回类型:
float
此函数的类型为:simple
tsfresh.feature_extraction.settings 模块
此文件包含用于控制在调用 extract_features 时提取哪些特征的方法/对象。有关特征命名,请参阅 特征计算器命名。
- class tsfresh.feature_extraction.settings.ComprehensiveFCParameters[source]
Bases:
PickableSettings创建一个新的 ComprehensiveFCParameters 实例。您必须将此实例传递给 extract_feature 实例。
它基本上是一个字典(也基于字典),它将字符串(与 feature_calculators.py 文件中的名称相同)映射到参数字典列表,这些参数应在该名称的函数被调用时使用。
只有作为此字典键的那些字符串(函数名)将在后续用于提取特征 - 因此,无论何时从此字典中删除一个键,您都会禁用此特征的计算。
您可以使用 settings 对象
>>> from tsfresh.feature_extraction import extract_features, ComprehensiveFCParameters >>> extract_features(df, default_fc_parameters=ComprehensiveFCParameters())
来提取所有特征(尽管这是默认设置),或者您可以将 ComprehensiveFCParameters 对象更改为其他类型(见下文)。
- class tsfresh.feature_extraction.settings.EfficientFCParameters[source]
Bases:
ComprehensiveFCParameters此类是 ComprehensiveFCParameters 类的子类,具有与其基类相同的功能。
唯一的区别是,计算成本高的特征不会被计算。这些特征通过属性“high_comp_cost”表示。
在调用 extract 函数时应使用此对象,例如
>>> from tsfresh.feature_extraction import extract_features, EfficientFCParameters >>> extract_features(df, default_fc_parameters=EfficientFCParameters())
- class tsfresh.feature_extraction.settings.IndexBasedFCParameters[source]
Bases:
ComprehensiveFCParameters此类是 ComprehensiveFCParameters 类的子类,具有与其基类相同的功能。
唯一的区别是仅包含需要 pd.Series 作为输入的特征。这些特征具有一个属性“input”,其值为“pd.Series”。
- class tsfresh.feature_extraction.settings.MinimalFCParameters[source]
Bases:
ComprehensiveFCParameters此类是 ComprehensiveFCParameters 类的子类,具有与其基类相同的功能。唯一的区别是,大多数特征计算器被禁用,只计算一小部分计算器。这些计算器通过一个名为“minimal”的属性表示。
在计算所有特征之前,使用此类进行快速设置测试,这可能需要一些时间,具体取决于您的数据集大小。
在调用 extract 函数时应使用此对象,例如
>>> from tsfresh.feature_extraction import extract_features, MinimalFCParameters >>> extract_features(df, default_fc_parameters=MinimalFCParameters())
- class tsfresh.feature_extraction.settings.PickableSettings(dict=None, /, **kwargs)[source]
Bases:
UserDict所有设置的基对象,它是一个可序列化的字典。对于用户指定的函数,设置字典可能包含函数作为键。不幸的是,这些函数无法轻易传输到多进程或多云设置中的 worker,因为它们默认不可序列化。因此,我们改变此类的 pickle 行为,在序列化完整对象之前,使用 cloudpickle 对字典的键进行序列化和反序列化。cloudpickle 能够序列化比 pickle 多得多的函数,并且 pickle 只会看到已经编码的键(而不是原始函数)。
- class tsfresh.feature_extraction.settings.TimeBasedFCParameters[source]
Bases:
ComprehensiveFCParameters此类是 ComprehensiveFCParameters 类的子类,具有与其基类相同的功能。
唯一的区别是,仅包含需要 DatetimeIndex 的特征。这些特征具有一个属性“index_type”,其值为 pd.DatetimeIndex。
- tsfresh.feature_extraction.settings.from_columns(columns, columns_to_ignore=None)[source]
创建从 kind 名称到 fc_parameters 对象(其本身是从特征计算器到设置的映射)的映射,以便仅提取 columns 中包含的特征。为此,对于 columns 中的每个特征名称,此方法将
将列名分割成 col、feature、params 部分
决定我们处理的是哪种特征(带/不带参数的聚合或应用)
将其添加到新的 name_to_function 字典中
设置参数
- 参数:
columns (list of str) – 包含特征名称的列表
columns_to_ignore (list of str) – 不包含 tsfresh 特征名称的列
- 返回:
准备好在 extract_features 函数中使用的 kind_to_fc_parameters 对象。
- 返回类型:
dict
模块内容
模块 tsfresh.feature_extraction 包含从时间序列中提取特征的方法