tsfresh.transformers 包
子模块
tsfresh.transformers.feature_augmenter 模块
- class tsfresh.transformers.feature_augmenter.FeatureAugmenter(default_fc_parameters=None, kind_to_fc_parameters=None, column_id=None, column_sort=None, column_kind=None, column_value=None, timeseries_container=None, chunksize=None, n_jobs=1, show_warnings=False, disable_progressbar=False, impute_function=None, profile=False, profiling_filename='profile.txt', profiling_sorting='cumulative')[source]
基类:
BaseEstimator,TransformerMixin与 Sklearn 兼容的估计器,用于计算从给定时间序列中提取的许多特征并将其添加到数据中。它本质上是
extract_features()的一个包装器。这些特征包括最小值、最大值或中位数等基本特征,以及傅里叶变换或统计检验等高级特征。有关所有可能特征的列表,请参阅模块
feature_calculators。每个添加特征的列名包含用于计算该特征的模块函数的名称。对于此估计器,两个数据集起着关键作用
包含时间序列数据的时间序列容器。此容器(格式见 数据格式)包含用于计算特征的数据。它必须能够按 ID 分组,这些 ID 用于识别哪个特征应附加到第二个数据框中的哪一行。
输入数据 X,特征将添加到其中。其行由索引标识,X 中的每个索引必须作为 ID 存在于时间序列容器中。
设想以下情景:您想对 10 种不同的金融股票进行分类,并且您拥有它们去年作为时间序列的发展情况。然后,您可以首先从股票的元信息(例如它们上市多久等)创建特征,并填写一个表格 - 每只股票的特征占一行。这就是输入数组 X,其中每行由例如股票名称作为索引标识。
>>> df = pandas.DataFrame(index=["AAA", "BBB", ...]) >>> # Fill in the information of the stocks >>> df["started_since_days"] = ... # add a feature
然后,您可以使用此估计器从股票的时间发展中提取所有特征。时间序列容器必须包含一个 ID 列,该列与 X 的索引相同。
>>> time_series = read_in_timeseries() # get the development of the shares >>> from tsfresh.transformers import FeatureAugmenter >>> augmenter = FeatureAugmenter(column_id="id") >>> augmenter.set_timeseries_container(time_series) >>> df_with_time_series_features = augmenter.transform(df)
特征计算的设置可以通过设置对象控制。如果您传递
None,则使用默认设置。请参阅ComprehensiveFCParameters获取更多信息。此估计器不选择相关特征,而是计算所有特征并将其添加到 DataFrame。有关计算和选择特征的信息,请参阅
RelevantFeatureAugmenter。有关参数 column_id、column_sort、column_kind 和 column_value 的含义描述,请参阅
extraction。- fit(X=None, y=None)[source]
此估计器不需要 fit 函数。它只是什么都不做,存在是为了兼容性原因。
- 参数:
X (Any) – 不需要。
y (Any) – 不需要。
- 返回值:
估计器实例本身
- 返回类型:
- set_timeseries_container(timeseries_container)[source]
设置用于计算特征的时间序列。有关时间序列容器的格式,请参阅
extraction。时间序列必须包含与稍后添加特征的 DataFrame(您将传递给transform()的那个)相同的索引。您可以随意多次调用此函数以稍后更改时间序列(例如,如果您想提取不同 ID 的时间序列)。- 参数:
timeseries_container (pandas.DataFrame or dict) – 作为 pandas.DataFrame 或 dict 的时间序列。有关格式,请参阅
extraction。- 返回值:
None
- 返回类型:
None
- transform(X)[source]
将使用 timeseries_container 计算的特征添加到输入 pandas.DataFrame X 中对应的行。
为了节省计算时间,您应该只在容器中包含您需要的时间序列。您可以使用方法
set_timeseries_container()设置时间序列容器。- 参数:
X (pandas.DataFrame) – 将添加计算的时间序列特征的 DataFrame。这*不是*包含时间序列本身的数据框。
- 返回值:
输入 DataFrame,但已添加特征。
- 返回类型:
pandas.DataFrame
tsfresh.transformers.feature_selector 模块
- class tsfresh.transformers.feature_selector.FeatureSelector(test_for_binary_target_binary_feature='fisher', test_for_binary_target_real_feature='mann', test_for_real_target_binary_feature='mann', test_for_real_target_real_feature='kendall', fdr_level=0.05, hypotheses_independent=False, n_jobs=1, chunksize=None, ml_task='auto', multiclass=False, n_significant=1, multiclass_p_values='min')[source]
基类:
BaseEstimator,TransformerMixin与 Sklearn 兼容的估计器,用于将数据集中的特征数量减少到仅与给定目标相关且重要的特征。它本质上是
check_fs_sig_bh()的一个包装器。检查通过检验以下假设进行
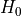 = 该特征不相关且不能添加
= 该特征不相关且不能添加对抗
 = 该特征相关且应保留
= 该特征相关且应保留使用几种统计检验(取决于特征和/或目标是否为二元)。使用 Benjamini Hochberg 过程,只拒绝
中的特征。此估计器 - 与大多数 sklearn 估计器一样 - 采用两步过程。首先,在已知目标的训练数据上进行拟合
>>> import pandas as pd >>> X_train, y_train = pd.DataFrame(), pd.Series() # fill in with your features and target >>> from tsfresh.transformers import FeatureSelector >>> selector = FeatureSelector() >>> selector.fit(X_train, y_train)
在此示例中,相关特征列表为空
>>> selector.relevant_features >>> []
特征重要性也是如此
>>> selector.feature_importances_ >>> array([], dtype=float64)
估计器会跟踪在训练步骤中相关的那些特征。如果您在训练后应用估计器,它将删除测试数据样本中的所有其他特征
>>> X_test = pd.DataFrame() >>> X_selected = selector.transform(X_test)
之后,X_selected 将只包含训练期间相关的特征。
如果您对特征有更多信息感兴趣,可以在拟合后查看成员
relevant_features。
tsfresh.transformers.per_column_imputer 模块
- class tsfresh.transformers.per_column_imputer.PerColumnImputer(col_to_NINF_repl_preset=None, col_to_PINF_repl_preset=None, col_to_NAN_repl_preset=None)[source]
基类:
BaseEstimator,TransformerMixin与 Sklearn 兼容的估计器,用于按列对 DataFrames 进行填充(impute),方法是将所有
NaNs和infs替换为同一列的平均值/极端值。它本质上是impute()的一个包装器。DataFrame 中出现的每个
inf或NaN都将被替换为-inf->min+inf->maxNaN->median
此估计器 - 与大多数 sklearn 估计器一样 - 采用两步过程。首先,调用
.fit函数,计算每列的最小值、最大值和中位数。其次,调用.transform函数,使用按列计算的最小值、最大值和中位数来替换出现的NaNs和infs。- fit(X, y=None)[source]
计算 DataFrame 中所有列的最小值、最大值和中位数。有关更多信息,请参阅
get_range_values_per_column()函数。- 参数:
X (pandas.DataFrame) – 用于计算最小值、最大值和中位数的 DataFrame
y (Any) – 不需要。
- 返回值:
包含计算出的最小值、最大值和中位数的估计器
- 返回类型:
Imputer
tsfresh.transformers.relevant_feature_augmenter 模块
- class tsfresh.transformers.relevant_feature_augmenter.RelevantFeatureAugmenter(filter_only_tsfresh_features=True, default_fc_parameters=None, kind_to_fc_parameters=None, column_id=None, column_sort=None, column_kind=None, column_value=None, timeseries_container=None, chunksize=None, n_jobs=1, show_warnings=False, disable_progressbar=False, profile=False, profiling_filename='profile.txt', profiling_sorting='cumulative', test_for_binary_target_binary_feature='fisher', test_for_binary_target_real_feature='mann', test_for_real_target_binary_feature='mann', test_for_real_target_real_feature='kendall', fdr_level=0.05, hypotheses_independent=False, ml_task='auto', multiclass=False, n_significant=1, multiclass_p_values='min')[source]
基类:
BaseEstimator,TransformerMixin与 Sklearn 兼容的估计器,用于从时间序列中计算相关特征并将其添加到数据样本中。
与许多其他 sklearn 估计器一样,此估计器分两步工作
在拟合阶段,使用由 set_timeseries_container 函数设置的时间序列计算所有可能的时间序列特征(如果特征未通过传入 feature_extraction_settings 对象手动更改)。然后,使用统计方法计算它们与目标的显著性和相关性,并仅使用 Benjamini Hochberg 过程选择相关的特征。这些特征在内部存储。
在转换步骤中,使用拟合步骤中哪些特征相关的信息,并从时间序列中提取这些特征。然后将这些提取的特征添加到输入数据样本中。
此估计器是 tsfresh 包中大部分功能的包装器。有关子任务的更多信息,请参阅以下单个模块和函数:
特征提取设置:
ComprehensiveFCParameters特征提取方法:
extract_features()提取的特征:
feature_calculators特征选择:
check_fs_sig_bh()
此估计器与
FeatureAugmenter的工作原理类似,不同之处在于此估计器只输出和计算相关特征,而另一个输出所有特征。对于此估计器,也有两个数据集起着关键作用
包含时间序列数据的时间序列容器。此容器(格式见
extraction)包含用于计算特征的数据。它必须能够按 ID 分组,这些 ID 用于识别哪个特征应附加到第二个数据框中的哪一行输入数据,特征将添加到其中。
设想以下情景:您想对 10 种不同的金融股票进行分类,并且您拥有它们去年作为时间序列的发展情况。然后,您可以首先从股票的元信息(例如它们上市多久等)创建特征,并填写一个表格 - 每只股票的特征占一行。
>>> # Fill in the information of the stocks and the target >>> X_train, X_test, y_train = pd.DataFrame(), pd.DataFrame(), pd.Series()
然后,您可以使用此估计器从股票的时间发展中提取所有相关特征
>>> train_time_series, test_time_series = read_in_timeseries() # get the development of the shares >>> from tsfresh.transformers import RelevantFeatureAugmenter >>> augmenter = RelevantFeatureAugmenter() >>> augmenter.set_timeseries_container(train_time_series) >>> augmenter.fit(X_train, y_train) >>> augmenter.set_timeseries_container(test_time_series) >>> X_test_with_features = augmenter.transform(X_test)
然后,X_test_with_features 将包含与 X_test 相同的信息(包含您可能添加的所有元信息),以及根据您提供的时间序列计算的一些相关时间序列特征。
请记住,您在 fit 或 transform 之前提供的时间序列必须包含 X 中存在的行的数据。
如果您的 set filter_only_tsfresh_features 设置为 True,则在使用此估计器之前在 X_train(或 X_test)中存在的手动创建的特征不会被触及。否则,这些特征也会被评估,并且可能因为不相关而被从数据样本中删除。
有关参数 column_id、column_sort、column_kind 和 column_value 的含义描述,请参阅
extraction。您可以通过传入设置来控制拟合步骤中的特征提取(转换步骤中的特征提取是自动完成的)以及拟合步骤中的特征选择。然而,如果您不传递任何标志,使用的默认设置通常是相当合理的。
- fit(X, y)[source]
使用来自
set_timeseries_container()的给定时间序列,并从中计算特征,然后将它们添加到数据样本 X 中(数据样本 X 可以包含其他手动设计的特征)。然后确定 X 中的哪些特征与给定的目标 y 相关。在内部存储这些相关特征,以便在转换步骤中只提取它们。
如果 filter_only_tsfresh_features 为 True,则只拒绝新自动添加的特征。如果为 False,则也会考虑 DataFrame 中已有的特征。
- 参数:
X (pandas.DataFrame or numpy.array) – 不含时间序列特征的数据框。索引行应存在于时间序列和目标向量中。
y (pandas.Series or numpy.array) – 用于定义哪些特征相关的目标向量。
- 返回值:
已拟合的估计器,包含哪些特征相关的信息。
- 返回类型:
- fit_transform(X, y)[source]
等同于先调用
fit()再调用transform();然而,这比分开执行这些步骤更快,因为它避免了对训练数据重新提取相关特征。- 参数:
X (pandas.DataFrame or numpy.array) – 不含时间序列特征的数据框。索引行应存在于时间序列和目标向量中。
y (pandas.Series or numpy.array) – 用于定义哪些特征相关的目标向量。
- 返回值:
一个数据样本,包含与 X 相同的信息,但已添加相关时间序列特征并删除了不相关信息(仅当 filter_only_tsfresh_features 为 False 时)。
- 返回类型:
pandas.DataFrame
- set_timeseries_container(timeseries_container)[source]
设置用于计算特征的时间序列。有关时间序列容器的格式,请参阅
extraction。时间序列必须包含与稍后添加特征的 DataFrame(您将传递给transform()或fit()的那个)相同的索引。您可以随意多次调用此函数以稍后更改时间序列(例如,如果您想提取不同 ID 的时间序列)。- 参数:
timeseries_container (pandas.DataFrame or dict) – 作为 pandas.DataFrame 或 dict 的时间序列。有关格式,请参阅
extraction。- 返回值:
None
- 返回类型:
None
- transform(X)[source]
在拟合步骤后,已知哪些特征是相关的,只从通过
set_timeseries_container()函数提供的时间序列中提取这些特征。如果 filter_only_tsfresh_features 为 False,则也删除数据框中不相关的、已有的特征。
- 参数:
X (pandas.DataFrame or numpy.array) – 要添加相关(并删除不相关)特征的数据样本。
- 返回值:
一个数据样本,包含与 X 相同的信息,但已添加相关时间序列特征并删除了不相关信息(仅当 filter_only_tsfresh_features 为 False 时)。
- 返回类型:
pandas.DataFrame
模块内容
模块 transformers 包含几个可在 sklearn pipeline 中使用的转换器。